


A proprietary question and answer system based on language models
- September 6, 2023
- 0
Over the past few months, everyone has been able to see the power of Generative AI, with ChatGPT being a huge eye-catcher. The basis are large language models


9621 Agnes Crossing, Lake Suzanneview, New Mexico Island 84604-9295.
Over the past few months, everyone has been able to see the power of Generative AI, with ChatGPT being a huge eye-catcher. The basis are large language models


Over the past few months, everyone has been able to see the power of Generative AI, with ChatGPT being a huge eye-catcher. The basis are large language models (large language models – LLMs): large-scale, parameter-rich neural networks trained on large amounts of text. Some applications of such LLMs are:
A popular application is answering questions. With the launch of ChatGPT, tools to answer questions about your own content are popping up en masse. The presentation is quite simple: upload your documents (PDF, Word, etc.) and you can start asking questions almost immediately, typically in a chatbot-like environment.
In this article we will show you how question answering system and tell us a bit more about the quality we can expect from the output.
The following diagram roughly shows which components are part of a question and answer system based on language models. The top part (blue) lists all the steps needed to prepare the content:
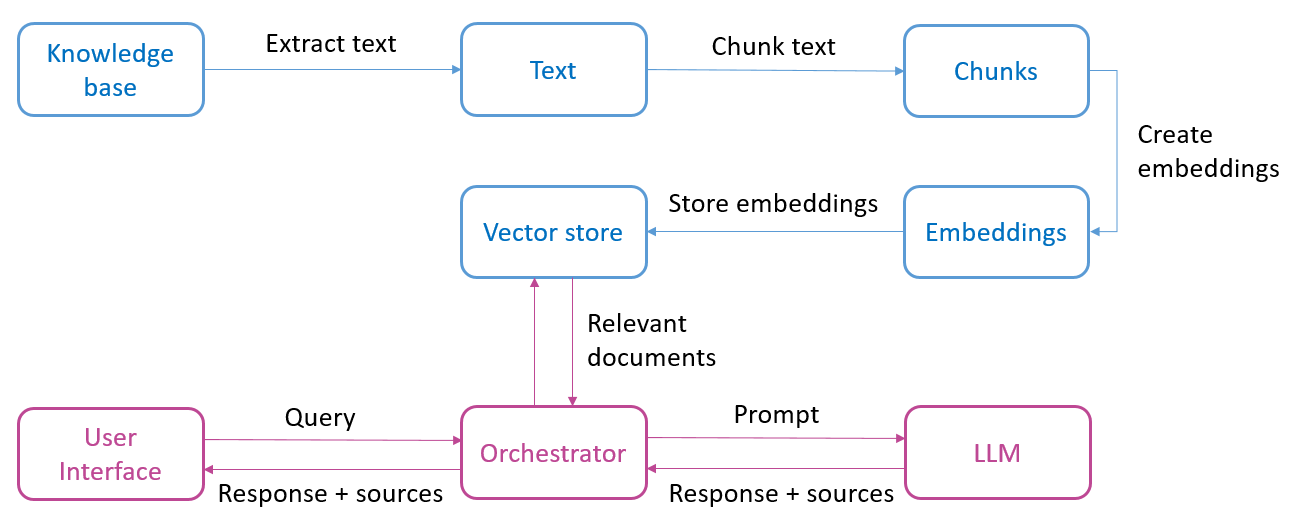
After this preparation phase, we as end users can ask the system a question (see the lower part of the figure). This is done as follows: The user question (query) is converted to embeds, which allows the documents to be looked up in vector storage (recreation) which are most semantically related to this question. then a prompt When sent to the language model, it is all the information needed to get an answer from the language model: the user’s original question, the relevant documents found, and the specific command (instruction) for the language model. Finally, we get back a generated response, if desired together with the sources (page numbers or website URLs).
We may wonder why we don’t immediately add all documents from the knowledge base as context to the language model. There are two main reasons for this. First, there is a limit to the size of context we can specify. For example, the popular GPT 3.5 Turbo model has a limit of 4000 tokens. Tokens are the smallest meaningful unit into which text can be broken down. A token can be a whole word, part of a word, or a punctuation mark, depending on the method used. tokenization.
A second reason is the cost of invoking a language model. This depends on the number of tokens in the input and output. The more context we provide with the input, the higher the cost.
Applications based on the above architecture can be developed quickly thanks to frameworks like Langchain. They typically provide abstractions to perform the tasks in the above scheme (extract text, parse text, create and store embeds) in a few lines of code. And they act as a kind of orchestrator to connect the user input to the vector store and the language model.
As an experiment, we started collaborating with Langchain to create a question answering application based on a PDF or web pages. With the necessary knowledge of the framework, this was set up very quickly.
The key question, of course, is how accurate are the answers we get back. Our experiments show that the answers are sometimes impressively good: precise, well summarized, and sometimes with correct justification, such as interpreting whether an amount from the question is above or below a certain limit.
But unfortunately we also have to realize that the answers are often inaccurate or incomplete, even completely wrong. Intuitively, one might think that this is related to the generative nature of language models and the phenomenon of hallucinations. However, an equally important factor is the recreation Step: Look up the most relevant pieces of text where the language model needs to find the information to formulate an answer. If the information useful for an answer is not in the provided body parts, we cannot expect the language model to return an accurate answer.
Regardless of where something goes wrong, there are a number of techniques to improve the quality of the output, including:
It would be nice to be able to build a system capable of answering questions about our own data with very little effort. However, the accuracy of the answer is still a big problem. There’s a good reason why such applications always come with a disclaimer stating that the answers may be inaccurate or wrong and that it’s always a good idea to double-check the result.
This is a contribution from Bert Vanhalst, IT consultant at Smals Research. This article was written on my own behalf and does not imply opinions on behalf of Smals. Are you interested in working at Smals? Then take a look at the current wide range of vacancies.
Source: IT Daily
As an experienced journalist and author, Mary has been reporting on the latest news and trends for over 5 years. With a passion for uncovering the stories behind the headlines, Mary has earned a reputation as a trusted voice in the world of journalism. Her writing style is insightful, engaging and thought-provoking, as she takes a deep dive into the most pressing issues of our time.





