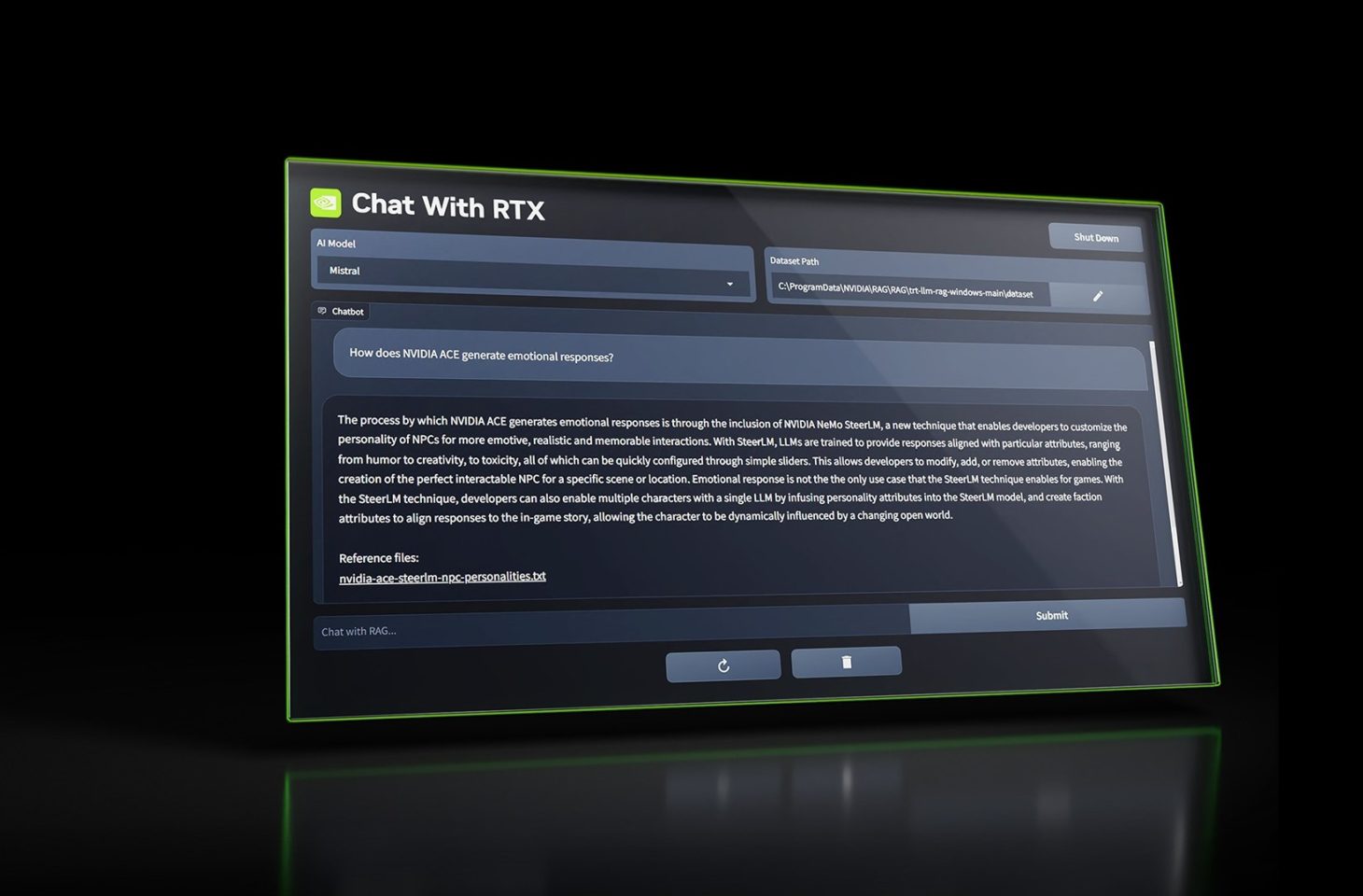
Nvidia will soon launch Chat with RTX. This is a tool that allows you to link local data to a large LLM to personalize its output.
Microsoft showed a demo of Chat with RTX at CES in Las Vegas. This is a demo application that allows you to expand the knowledge of an LLM with your own relevant data. The tool allows you to link your own data, including documents and videos, to the LLM so that this data is included in your question. In theory, the answers will be much more accurate.
Nvidia’s tool leverages the new TensorRT-LLM library for Windows, which enables an Nvidia Tensor GPU to accelerate AI workloads. Additionally, Chat with RTX is based on a technique called RAG, which stands for Get extended generation.
External sources
RAG ensures that you can easily link an LLM to external sources that always provide context for the questions you ask. For example, you can use Chat with RTX to link the latest version of your product catalog to an LLM and then easily ask questions about that catalog to the AI chatbot.
Chat with RTX initially runs locally. This allows you to easily add relevant data to your prompts using a compatible computer. The app works with plain text, PDF, doc(x), XML and even YouTube videos. According to Nvidia’s demo, the trained LLM you link the data to also appears to be running locally. This is then accelerated by the RTX GPU.