Opera never appears in the lists of the most used web browsers, but it should always appear among the most innovative and recommended for many reasons. Obviously, not everything is perfect, and those responsible never had the muscle to compete on a level playing field with Google Chrome, Apple Safari, and Microsoft Edge. The one with which it usually goes into the fight most directly is therefore Firefox, which is already quite far from its best times, although considering the huge dominance of Chrome, the others are in a rather narrow band of the table.
The latest examples of its innovative capacity can be found, as it could not be otherwise, with many artificial intelligence-based features added to the browser practically throughout 2023 and so far in 2024. The latest progress In this sense, which was also one of the most important , is to allow Opera to run multiple LLMs locally, as we told you here, and we also learned a few months ago that the company was developing a browser focused on artificial intelligence. iOS.
It is clear that the technology companies responsible for browsers, and Opera is no exception, joined the artificial intelligence revolutionwith the understanding that features based on it can make a big difference in this regard. Let’s recall that Microsoft gave the initial signal by announcing that Edge would incorporate Copilot (then Bing) technology, and that the first response in this regard, less than a week later, was precisely Opera’s response.

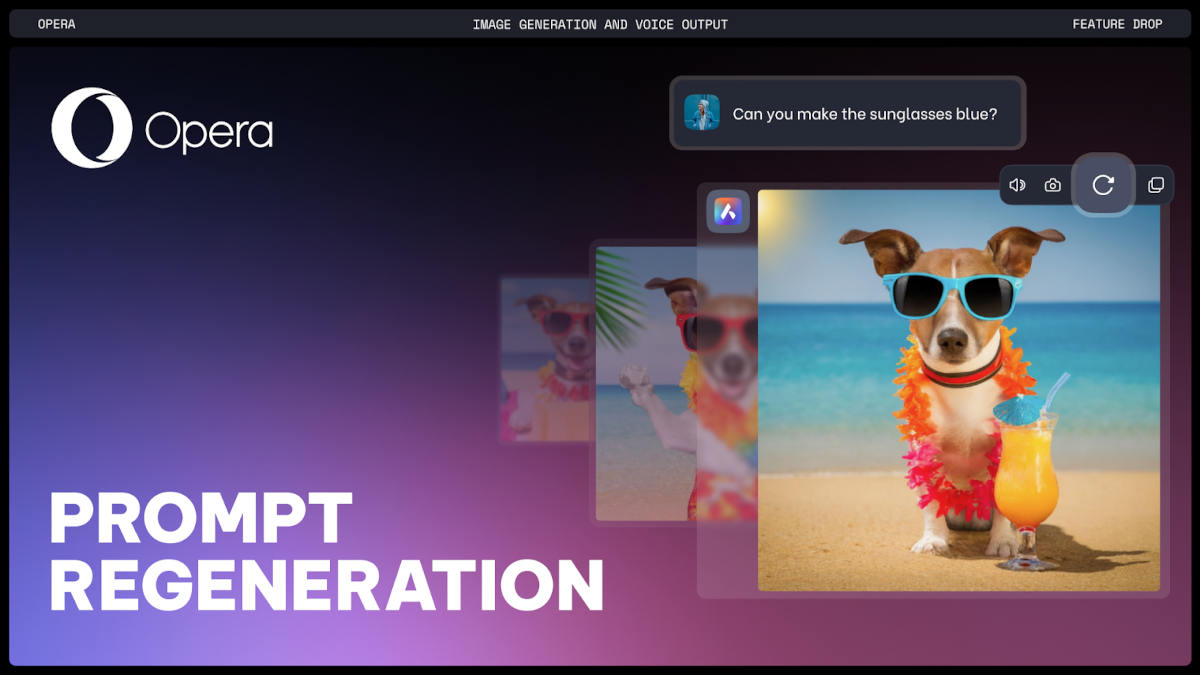
Until now, the browser’s AI-based features have been limited to text, but today we find two new features that expand the playing field because, as we read on its official blog, Opera adds image generation and voice output functions, both included in Aria’s already extensive catalog of AI features. Of course, these features are currently only available in Opera One Developer, the beta version of which we have already explained here how you can download and use it.
As with other services of this type, image generation using Opera AI It is based on input provided by the user in a text prompt and is based on Google Deep Mind’s Image 2 model. Once we have the first image, we can use the button with the circular arrow shown in the upper left corner to create the image again with the same prompt, or we can ask it to make adjustments to it as many times as we want until we get the desired result.
On the part of the function voice output It’s pretty self-explanatory. When we received a response from Aria, when we hover over it, a floating menu appears in the upper right corner with several controls, including one with an icon that represents the speaker. Clicking on it will start reading the text, which we can pause if necessary by clicking the same button again.





















