


Stability AI launches text-to-audio platform
- September 15, 2023
- 0
Open source AI company Stability AI has proposed the Stable Audio platform, a model that generates audio from text prompts. British company Stability AI has launched Stable Audio,


9621 Agnes Crossing, Lake Suzanneview, New Mexico Island 84604-9295.
Open source AI company Stability AI has proposed the Stable Audio platform, a model that generates audio from text prompts. British company Stability AI has launched Stable Audio,


Open source AI company Stability AI has proposed the Stable Audio platform, a model that generates audio from text prompts.
British company Stability AI has launched Stable Audio, a text-to-audio conversion platform. This is just a few months after StableStudio, a text-to-image platform.
The AI for this platform is trained on more than 800,000 audio files containing music, sound effects and samples of a single instrument. Together, these files form a dataset of more than 19,500 hours of audio.
In addition, there was also the corresponding textual metadata. All of this happened through a deal with a stock music provider, AudioSparx.
This means that Stability AI no longer takes any risks regarding the origin of the training data. There is an ongoing case from Getty Images regarding the use of images for stable diffusion training.
Stable Audio uses latent diffusion models made up of individual components, similar to Stable Diffusion. These parts are:
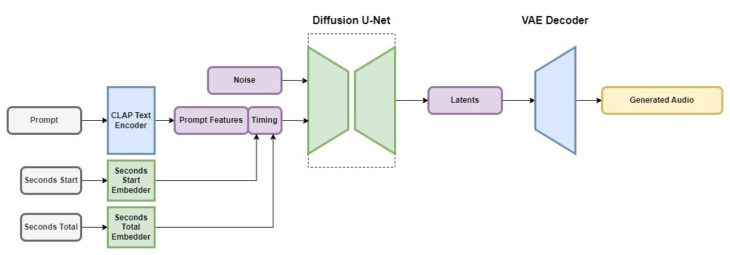
To train the AI with the text prompts, Stability AI uses a CLAP model because this system allows the text to contain information about the connection between words and sounds. A text token is sent to the diffusion model via this text encoder.
For the timing of the audio, the training considers two numbers: the start time at which part of an audio fragment is used and its total duration. For example, if a training clip lasts sixty seconds, but the training only covered the last forty seconds, the first value is 20 (seconds) and the second value is 60. This form of training allows Stability AI to produce audio clips of a specific length.
The platform can currently produce stereo clips that are 95 seconds long at a time Sample Rate of 44.1 kHz (samples are the audio equivalent of pixels in images). This happens within a second, with an Nvidia A100 GPU.
Source: IT Daily
As an experienced journalist and author, Mary has been reporting on the latest news and trends for over 5 years. With a passion for uncovering the stories behind the headlines, Mary has earned a reputation as a trusted voice in the world of journalism. Her writing style is insightful, engaging and thought-provoking, as she takes a deep dive into the most pressing issues of our time.





